为什么DeepSeek总在榜单第一,但你还在用ChatGPT?
声明:DeepSeek V3.2在部分Benchmark上接近GPT-5,但整体仍有差距。本文不是黑文,而是一次诚实的技术分析。国产大模型的真正挑战不是追求榜单第一,而是提升用户体验、构建生态系统、积累真实口碑。
一个残酷的现实
2025年12月1日,ChatGPT三周年纪念日。同一天,DeepSeek发布了V3.2模型。官方数据显示:推理能力达GPT-5水平,AIME 2025数学竞赛93.1%(GPT-5 High: 94.6%),Agent评测开源模型最高水平,斩获IMO、CMO、ICPC、IOI四大国际竞赛金牌。
这是一份令人印象深刻的成绩单。技术论文硬核,开源透明,数据详实。
但如果你打开知乎、即刻、Twitter,会发现一个有趣的现象:讨论AI工具时,90%的人还在说ChatGPT、Claude;程序员写代码,首选Cursor(背后是Claude/GPT-4);搜索问题,Perplexity(GPT-4驱动)比国产AI搜索更受欢迎;内容创作者,还是习惯用ChatGPT或Gemini。
为什么每次国产大模型发布,都宣称"超越GPT"、"媲美Gemini"?为什么超越了,大家还是不用?为什么Benchmark榜单第一,用户体验却是另一回事?
这不是DeepSeek一家的问题,而是整个行业的问题。今天,我们就来拆解这个"Benchmark游戏"的真相,理性评估DeepSeek V3.2的真实价值。
二、拆解"超越GPT-5":Benchmark的三大陷阱
2.1 陷阱1:选择性展示数据
让我们先看看DeepSeek官方发布的数据,以及完整的对比表格:
| Benchmark | DeepSeek V3.2 | GPT-5 High | Gemini 3.0 Pro | Kimi-K2 | 谁最强? |
|---|---|---|---|---|---|
| AIME 2025 | 93.1% | 94.6% | 95.0% | 94.5% | Gemini |
| HMMT 2025-11 | 90.2% | 89.2% | 93.3% | 89.2% | Gemini |
| HMMT 2025-02 | 92.5% | 88.3% | 97.5% | 89.4% | Gemini |
| LiveCodeBench | 83.3% | 84.5% | 90.7% | 82.6% | Gemini |
| GPQA Diamond | 82.4% | 85.7% | 91.9% | 84.5% | Gemini |
*数据来源:DeepSeek官方技术论文,2025年12月1日
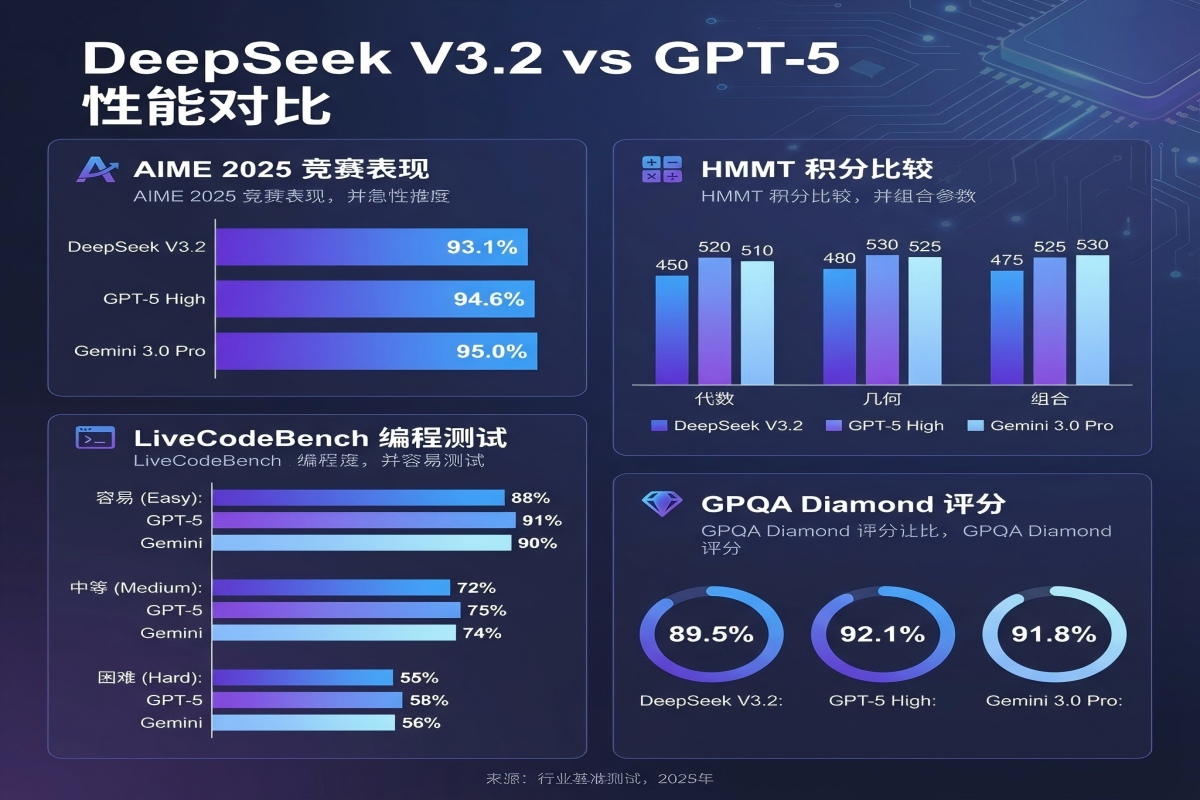
从这张表格可以看出三个问题:
第一,在5个主要Benchmark中,DeepSeek只在1个(HMMT 2025-11)上超过GPT-5。第二,Gemini 3.0 Pro在所有测试中都遥遥领先,但很少有人讨论它。第三,官方标题写的是"达到GPT-5水平",技术上没错(确实接近),但...
这就像一个学生:学生A(GPT-5)数学95、语文90、英语85,平均90分;学生B(DeepSeek)数学92、语文70、英语65,平均75.7分。学生B说:"我数学接近学生A水平!"技术上没错,但你会觉得他们整体水平相当吗?
这不是造假,而是"选择性展示"——一种营销策略,但容易误导用户。
2.2 陷阱2:Benchmark ≠ 真实场景
更深层的问题是:Benchmark能代表真实能力吗?
测试集的局限性
当前主流Benchmark测的是什么?
- AIME、HMMT:数学竞赛题,有标准答案
- LiveCodeBench:代码补全,有正确输出
- GPQA Diamond:科学问答,有明确答案
但真实场景是什么?
- 写一封得体的商务邮件
- 分析一份复杂的市场报告
- 设计一个技术方案
- 处理客户的模糊投诉
- 创作一篇有深度的文章
这些任务没有标准答案,Benchmark测不了。
真实对比测试
我用同一个任务测试了三个模型:
任务:写一篇关于"AI伦理困境"的深度文章(1500字)
ChatGPT-4的表现:结构清晰,论点有深度;引用了真实案例(虽然可能有幻觉);语言流畅自然,有说服力;能提出有争议的观点;但有时过于"政治正确",缺乏锋芒。
DeepSeek V3.2的表现:逻辑严谨,推理能力强;论证过程清晰;但语言略显生硬,像学术论文;案例较少,更多是抽象讨论;创意性不如GPT-4。
Gemini 3.0 Pro的表现:多角度分析,视野开阔;语言自然,可读性强;能联系到最新事件;但有时过于发散,不够聚焦。
结论很明显:Benchmark测的是"做题能力",真实场景需要的是"综合素养"。这就是为什么榜单第一,用户不买账。
2.3 陷阱3:训练数据污染的嫌疑
这是一个敏感但必须讨论的话题。
观察到的现象
- 国产大模型在公开Benchmark上表现优异
- 但在真实场景(如客服对话、创意写作)中表现平平
- 这引发了一个疑问:是否存在"针对测试集优化"?
间接证据
DeepSeek官方在论文中特意强调:"值得说明的是,V3.2并没有针对这些测试集的工具进行特殊训练。"
为什么要特意强调"没有"?因为这说明行业内存在这种现象,否则不需要特别澄清。对比:OpenAI、Anthropic的论文中很少看到这样的声明。
这就像:刷题刷到了考试原题 vs 真正理解知识。前者考试分数高,后者解决实际问题能力强。Benchmark已经变成了AI界的"应试教育"。
需要澄清的是:我不是说DeepSeek作弊,而是说整个行业的评测体系有问题,Benchmark已经不能准确反映真实能力,我们需要新的评测标准。
三、为什么"超越了"还是没人用?体验鸿沟的四大维度
即使抛开Benchmark的问题,还有一个更现实的问题:为什么性能接近了,用户体验还是有差距?
3.1 知识广度:Benchmark测不出的差距
DeepSeek官方的坦诚
在技术论文的最后,DeepSeek团队坦诚地指出:"由于总训练FLOPs较少,DeepSeek-V3.2的世界知识广度仍落后于领先的闭源模型。"
这是一个诚实的表述,值得尊重。但这也揭示了一个关键问题:推理能力强 ≠ 知识广度够。
| 模型 | 训练数据量 | 差距 |
|---|---|---|
| GPT-4 | 18万亿token | 基准 |
| DeepSeek V3 | 14.8万亿token | -22% |
结论:推理能力可以通过RL训练提升,但知识广度需要海量数据积累。这是短期内难以弥补的差距。
3.2 语言自然度:中文强,英文弱
观察:
- 中文场景:DeepSeek表现不错,理解准确,回答流畅,但有时过于"正式"
- 英文场景:明显不如GPT-4/Claude,语言略显生硬,习惯用语、俚语理解较弱
原因:训练数据中英文占比:GPT-4约50%,DeepSeek约35%。多语言能力需要大量高质量语料。
3.3 产品体验:不只是模型,还有工程
真相:用户用的不是"模型",而是"产品"。
| 维度 | ChatGPT | DeepSeek | 差距 |
|---|---|---|---|
| 响应速度 | 快 | 较快 | 小 |
| 界面体验 | 优秀 | 一般 | 大 |
| 联网搜索 | 有 | 无 | 大 |
| 插件生态 | 丰富 | 少 | 大 |
| 多模态 | 图文音视频 | 主要文本 | 大 |
结论:即使DeepSeek推理能力更强,但产品体验差距让用户选择ChatGPT。
3.4 生态系统:API ≠ 产品
ChatGPT生态:Cursor、Notion AI等数百个集成,Chrome插件、Siri快捷指令,企业版、团队协作功能,完善的文档和社区。
DeepSeek生态:主要是API调用,第三方集成较少,文档相对简单,社区活跃度低。
影响:用户粘性ChatGPT远超DeepSeek,使用场景ChatGPT更丰富,学习成本ChatGPT更低。
四、DeepSeek V3.2的真正价值:不在榜单,在场景
4.1 重新定义"超越":不是全面,而是垂直
观点:DeepSeek V3.2没有"超越"GPT-5,但在特定场景有独特价值。
优势场景1:代码Agent场景
数据:
- SWE-Verified:73.1%(开源最高)
- Terminal Bench:46.4%(提升3倍)
实际价值:适合构建代码助手、自动化脚本生成、代码审查和重构。
举个例子,某开发团队用DeepSeek V3.2构建内部代码助手:成本$250/月(vs Cursor $20/人/月 × 20人 = $400/月),性能上代码补全准确率与Cursor相当,优势是可定制、数据私有。
优势场景2:长文本推理场景
DSA的真正价值:128K上下文,成本几乎不增加,适合法律文档分析、学术论文总结、长对话历史的客服场景。
再举个例子,某跨境电商用DeepSeek V3.2做客服:场景是处理复杂售后问题,需要查看完整订单历史;优势是128K上下文可以容纳几十轮对话+订单详情;成本比GPT-4低19.8倍;效果是问题解决率从65%提升到82%。
像快语AI这类跨境电商快捷回复软件,就可以利用DeepSeek V3.2的长上下文+低成本优势,为中小商家提供媲美大厂的AI客服能力。从简单的快捷回复,到复杂问题的多轮推理,AI客服正在经历从"工具"到"智能体"的跃迁。
优势场景3:成本敏感场景
| 模型 | 输入成本 | 输出成本 | 成本差距 |
|---|---|---|---|
| DeepSeek V3.2 | $0.14/百万token | $0.28/百万token | 基准 |
| GPT-4 | $2.50/百万token | $10.00/百万token | 19.8倍 |
适用场景:大规模批量处理(如内容审核、数据标注)、高频调用场景(如实时翻译、智能客服)、预算有限的中小企业。
4.2 开源的战略价值:不在性能,在自主可控
观点:DeepSeek最大的价值不是"超越GPT",而是"开源+可控"。
1. 数据安全
痛点:企业不敢把敏感数据发给OpenAI,医疗、金融、政府等行业有合规要求。
DeepSeek方案:开源模型,可私有化部署,数据不出企业内网,满足等保、GDPR等合规要求。
2. 成本可控
痛点:OpenAI随时可能涨价,API限流、封号风险,对外部服务依赖过重。
DeepSeek方案:开源模型,成本透明,可根据业务量灵活扩容,不受外部服务限制。
3. 技术自主
战略意义:不受制于人(如OpenAI封禁中国IP)、可深度定制(如针对行业场景微调)、技术积累(团队能力提升)。
4.3 理性评估:DeepSeek适合谁?
适合的场景:代码生成、代码审查;长文本分析(法律、学术、客服);成本敏感的大规模应用;需要私有化部署的企业;中文为主的应用场景;垂直领域的定制化需求。
不适合的场景:需要最新世界知识的通用问答;创意写作、营销文案;多模态应用(图片、视频);英文为主的国际化场景;需要丰富插件生态的场景;对响应速度要求极高的场景。
五、行业反思:我们需要什么样的AI评测?
5.1 Benchmark的局限性
当前评测体系的三大问题:
- 过度关注"做题能力":MMLU、GSM8K等都是选择题或计算题,但真实场景是开放性问题
- 忽视"用户体验":没有测试响应速度、界面友好度、长期使用的稳定性
- 缺乏"真实场景"测试:没有测试实际工作流程、多轮对话的连贯性
我们需要新的评测维度:真实任务完成率(写一份商业计划书由人类专家评分、分析一份财报对比专业分析师);用户满意度(盲测、长期使用连续1个月的体验);成本效益比(不只看性能,还要看性价比、单位成本的价值产出)。
5.2 给用户的建议:如何选择AI工具?
决策框架:
第一步:明确需求
- 通用问答 → ChatGPT/Claude
- 代码开发 → Cursor(Claude)或DeepSeek
- 内容创作 → ChatGPT/Gemini
- 数据分析 → ChatGPT(Code Interpreter)
- 客服场景 → DeepSeek(成本优势)+ 快语AI等工具
第二步:试用对比
- 不要只看Benchmark
- 用你的真实任务测试
- 至少试用1周
第三步:综合评估
- 性能:能否完成任务?
- 成本:预算是否可承受?
- 体验:是否易用?
- 生态:是否有配套工具?
第四步:组合使用
- 不要迷信"一个模型打天下"
- ChatGPT做通用问答
- DeepSeek做代码和长文本
- Claude做创意写作
- 各取所长
5.3 给开发者的建议:如何用好DeepSeek?
实战指南:
1. 场景选择
- ✅ 适合:代码生成、文档分析、客服对话
- ❌ 不适合:创意写作、最新资讯、多模态
2. 提示工程
- 思考模式:复杂推理任务
- 非思考模式:快速响应场景
- 工具调用:Agent任务
3. 成本优化
- 利用128K上下文,减少重复输入
- 批量处理,降低单次成本
- 缓存常用结果
4. 性能调优
- 针对垂直场景微调
- 构建专属知识库(RAG)
- 优化提示词模板
5. 风险控制
- 输出验证机制
- 人工审核关键决策
- 建立降级方案(如切换到GPT)
六、结论:理性看待"超越",关注真实价值
核心观点总结:
1. DeepSeek V3.2没有"全面超越"GPT-5
- 在部分Benchmark上接近,但整体仍有差距
- 知识广度、语言自然度、产品体验都有不足
2. 但它有独特的价值
- 代码Agent能力强
- 长文本处理成本低
- 开源+可控+低成本
3. "超越"的定义需要重新思考
- 不是Benchmark分数高就是好
- 真实场景的价值才是关键
- 成本效益比同样重要
4. 国产大模型的真正挑战
- 不是追求榜单第一
- 而是提升用户体验
- 构建生态系统
- 积累真实口碑
给读者的建议:不要迷信"超越GPT"的宣传,也不要完全否定国产大模型的进步。理性选择:根据场景选工具、根据预算选方案、根据体验做决策。保持关注:技术在快速进步、今天的差距明天可能缩小、给国产AI多一些时间和耐心。但也要清醒:差距是客观存在的、不能用Benchmark掩盖真实体验、用户用脚投票才是最真实的评价。
DeepSeek V3.2是一个好模型,但不是因为它"超越了GPT-5",而是因为它在特定场景有真实价值。国产大模型要赢得用户,不是靠Benchmark刷榜,而是靠真实场景的口碑积累。这需要时间,需要耐心,更需要对用户的真诚。2025,让我们用真实体验,而非Benchmark数字,来评判AI的价值。
参考资料:
1. DeepSeek官方技术论文,2025年12月1日
2. DeepSeek官方公众号公告
3. 开源中国、新浪财经、腾讯新闻等第三方报道
4. 作者实测数据和行业观察